吴恩达机器学习课程笔记第10章

吴恩达机器学习课程笔记第10章
Justin本系列文章如果没有特殊说明,正文内容均解释的是文字上方的图片
机器学习 | Coursera
吴恩达机器学习系列课程_bilibili
@TOC
10 应用机器学习的建议
10-1 决定下一步做什么
10-2 评估假设函数

随机选择数据集中的70%作为训练集,30%作为测试集,将数据集分为两个部分
- 首先根据训练集计算出参数$\Theta$
- 把参数$\Theta$代入测试集计算代价函数的值(这里是线性回归的代价函数,逻辑回归的代价函数同理):
$$J_{test}(θ)=\frac{1}{2m_{test}}\sum_{i=1}^{m_{test}}(h_θ(x^{(i)}{test})-y^{(i)}{test})^2$$

逻辑分类中有另一种形式的测试度量,称作错误分类或0/1错误分类,计算过程如上图
10-3 模型选择和训练、验证、测试集
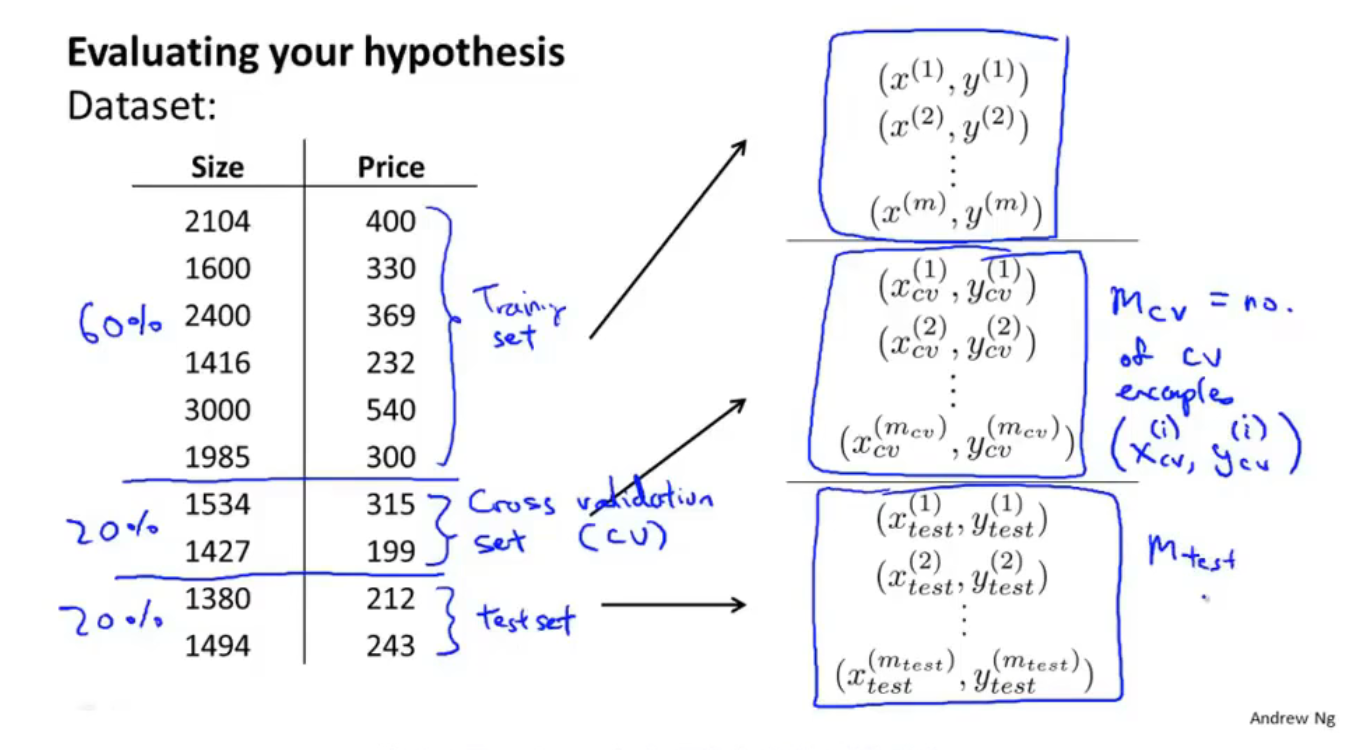
随机选择数据集中的60%作为训练集(Training Set),20%作为交叉验证集(验证集,Cross Validation Set,cv),20%作为测试集(Test Set),将数据集分为三个部分
上图,计算训练误差、验证误差和测试误差
用$d$来表示假定函数的多项式的最高次幂
- 先用训练集求每一个假定函数的代价函数$J(\Theta)$取到最小值时$\Theta$的值,再把这个求得的$\Theta$代入交叉验证集求得$J_{cv}(\Theta)$,对每一个假定函数进行以上步骤的计算,得到$d=1,…,10$的10个代价函数的值,取最小的那个,这里假定是$d=4$,再使用$d=4$时的$\Theta$代入测试集得到泛化误差
10-4 判断偏差与方差
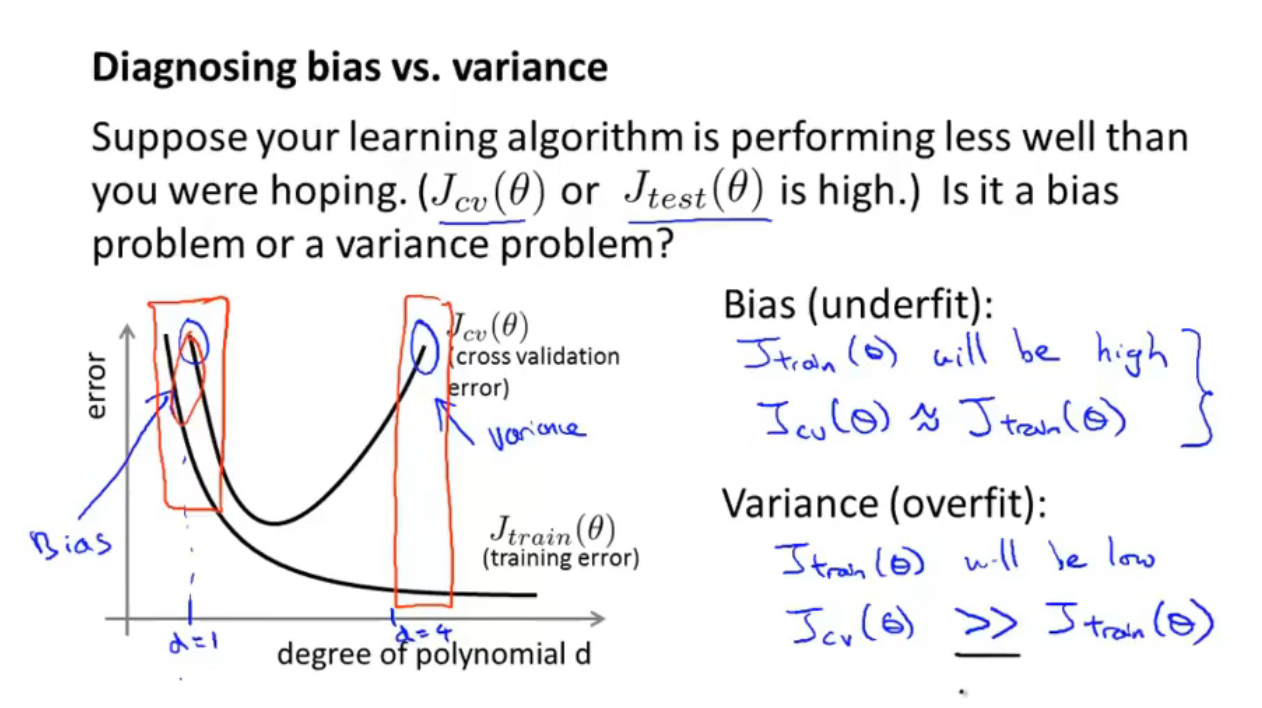
上图坐标系$y$轴为误差,$x$轴为$d$(多项式最高次幂)的大小
以上图为例,
- 当$d$过小时,出现欠拟合(underfit),偏差(bias)过大,此时的训练集误差$J_{train}(\Theta)$很大,并且$J_{cv}(\Theta)\approx J_{train}(\Theta)$
- 当$d$过大时,出现过拟合(overfit),方差(variance)过大,此时的训练集误差$J_{train}(\Theta)$很小,并且$J_{cv}(\Theta)>> J_{train}(\Theta)$
10-5 正则化和偏差、方差
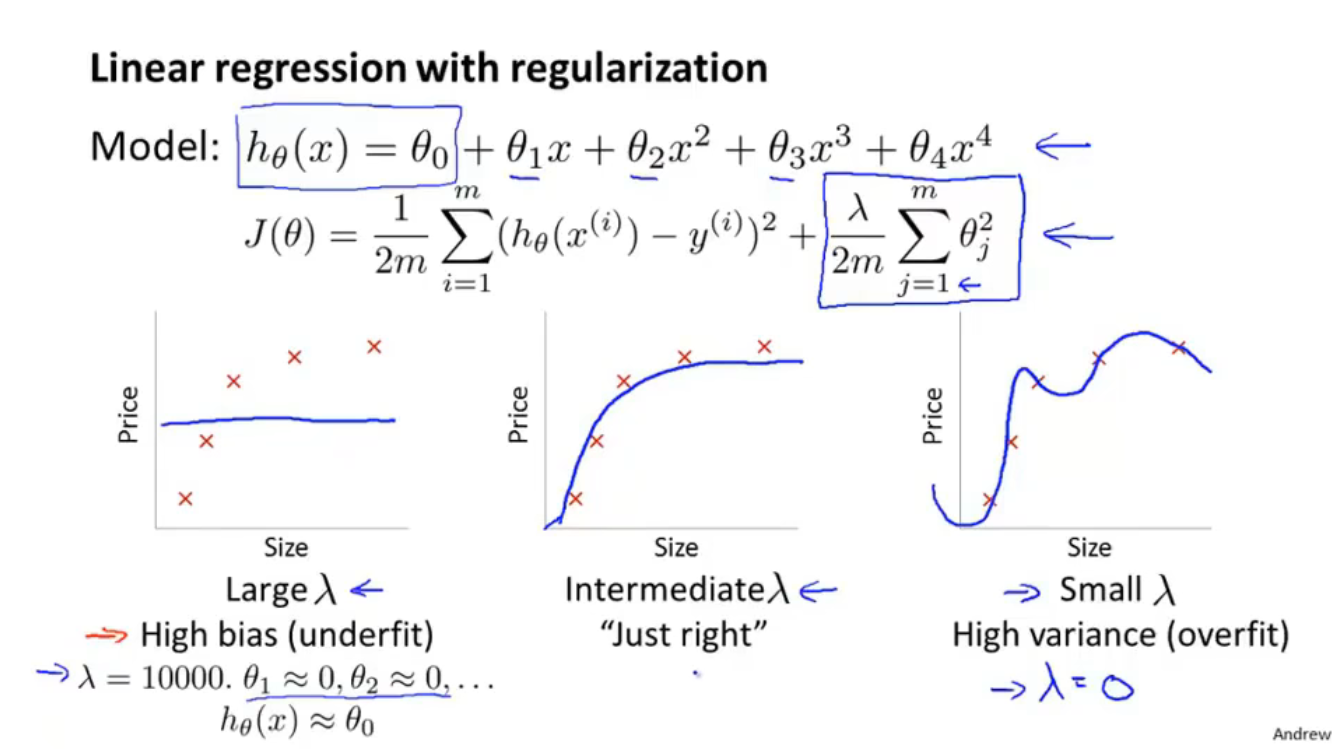
- 若正则化参数$\lambda$过大,会导致欠拟合,高偏差,并且参数$\theta_1\approx 0,\theta_2\approx 0,…$,假定函数的结果$h_{\theta}(x)\approx \theta_0$,如上图最左侧坐标系
- 若正则化参数$\lambda$过小,会导致过拟合,高方差,如上图最右侧坐标系
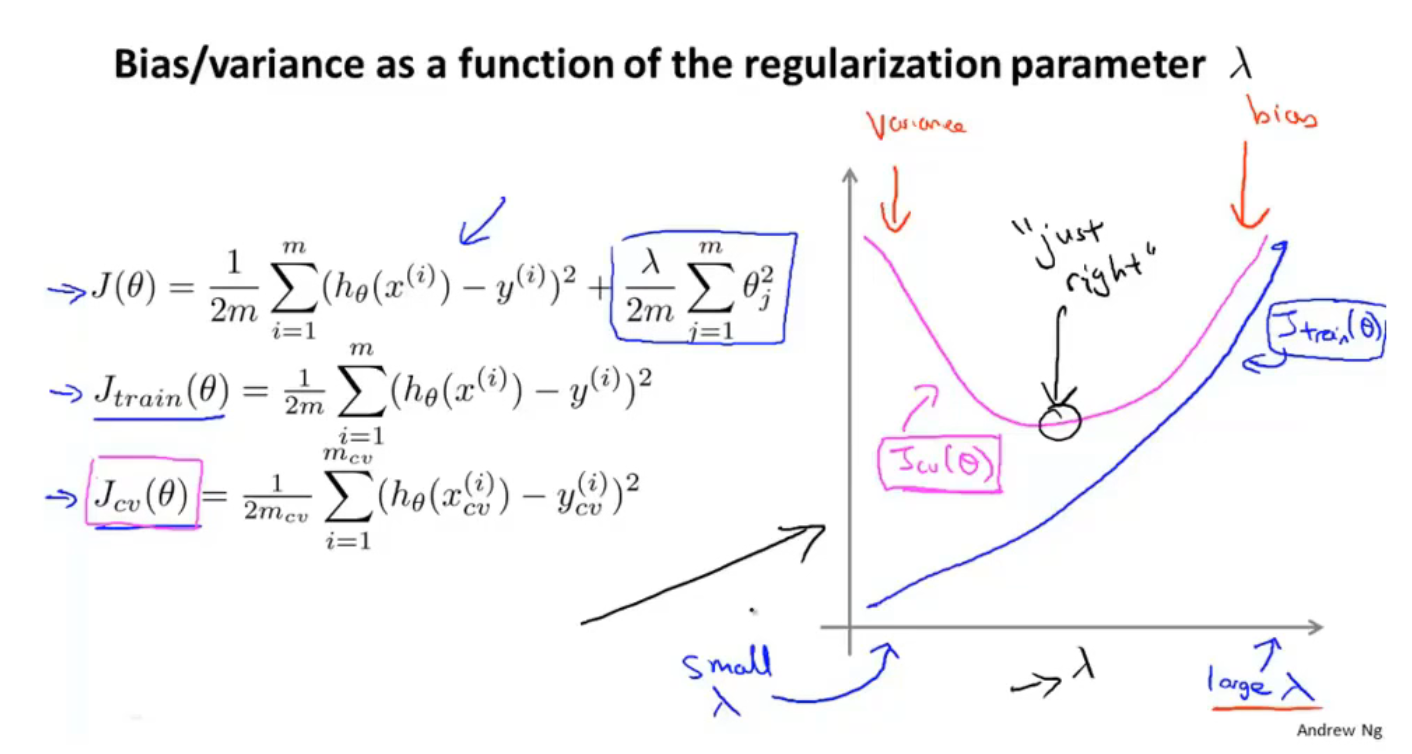
使用不带正则化项的$J_{train}(\Theta)、J_{cv}(\Theta)、J_{test}(\Theta)$
$J(\Theta)$取下图中的带正则化项的代价函数 - 首先取多种$\lambda$的情况,这里从0,0.01开始,下一个$\lambda$是上一个的两倍,一直取到$\lambda=10.24$,由于此时小数部分对结果影响不大,所以也可以直接取$\lambda=10$
- 将每一种情况的$\lambda$代入带正则化项的代价函数$J(\Theta)$中,这里共能得到12个不同的$\Theta$值
- 再把这12个$\Theta$代入到交叉验证集代价函数$J_{cv}(\Theta)$中,注意这里的$J_{cv}(\Theta)$是不带正则化项的,最后得到12个不同的$J_{cv}(\Theta)$值
- 取最小的那个$J_{cv}(\Theta)$值对应的$\lambda$(这里认为第5个$\lambda$是最合适的)代入到测试集的代价函数$J_{test}(\Theta)$中,计算泛化误差,注意这里的$J_{test}(\Theta)$也是不带正则化项的

10-6 学习曲线
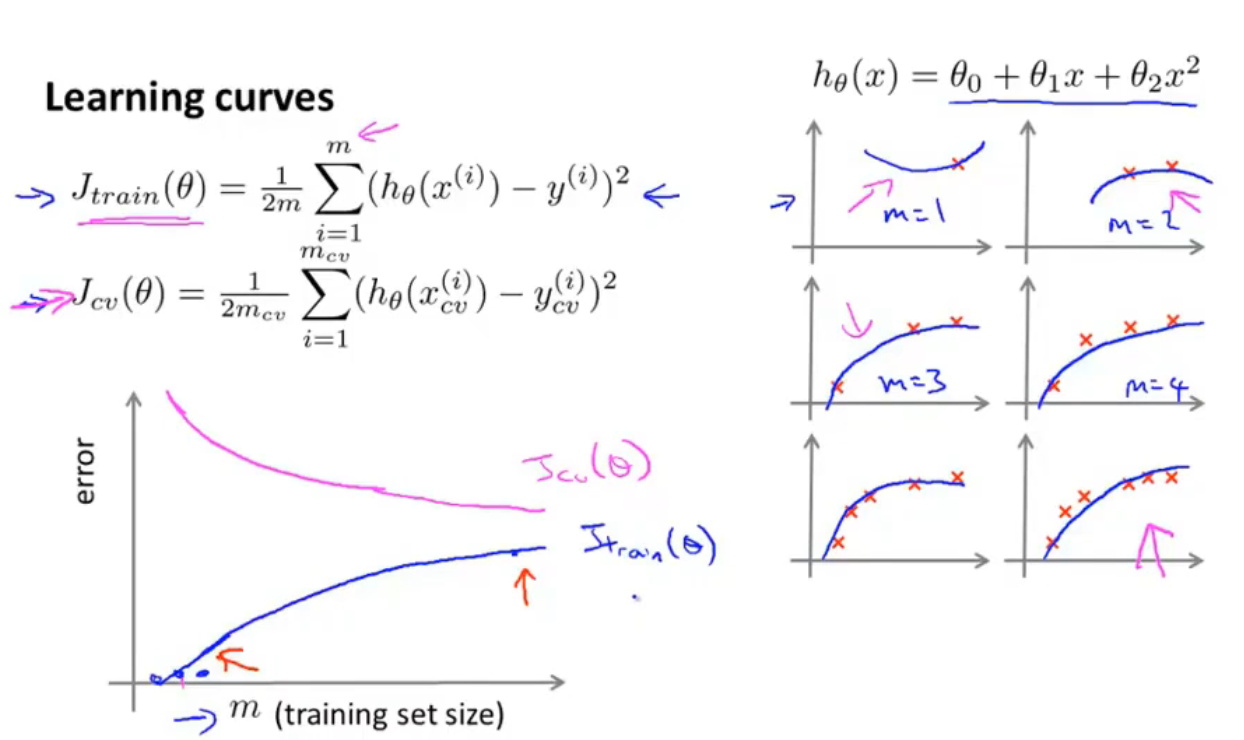
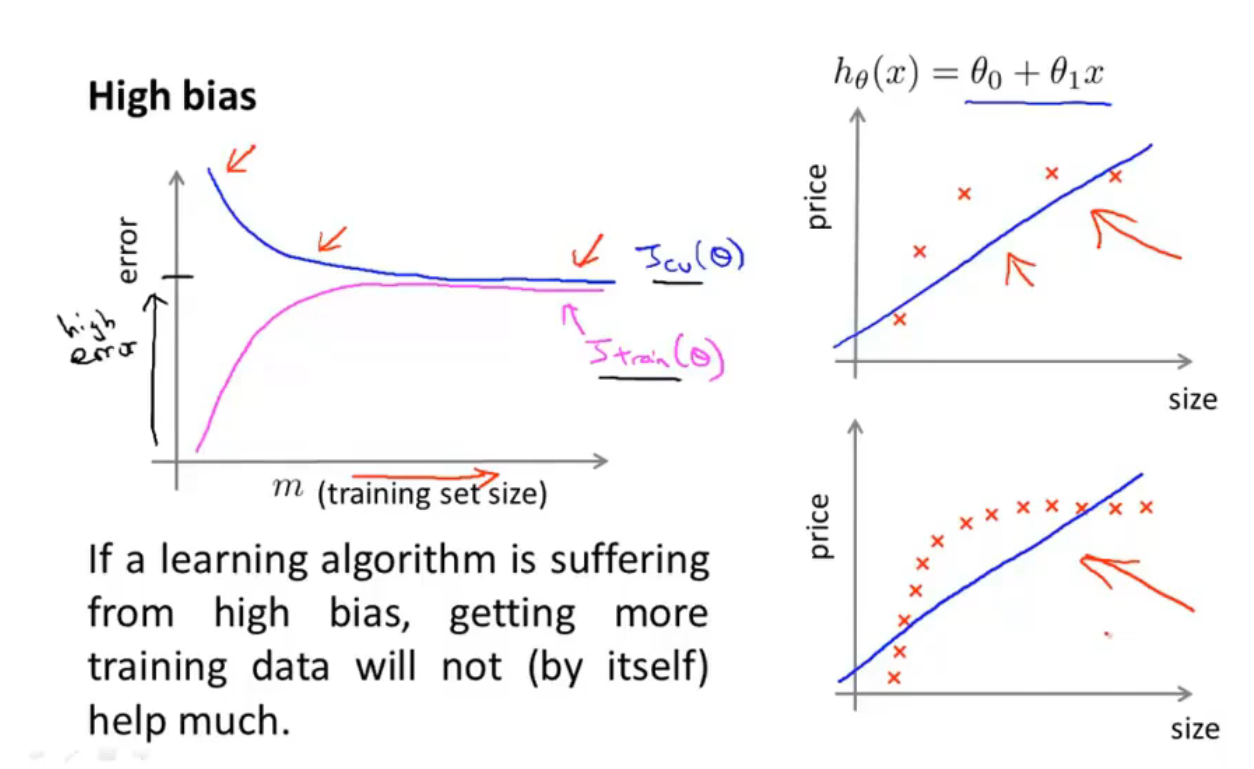
如上图是高偏差/欠拟合的情形
此时增加数据集数量对于误差的缩小没有明显帮助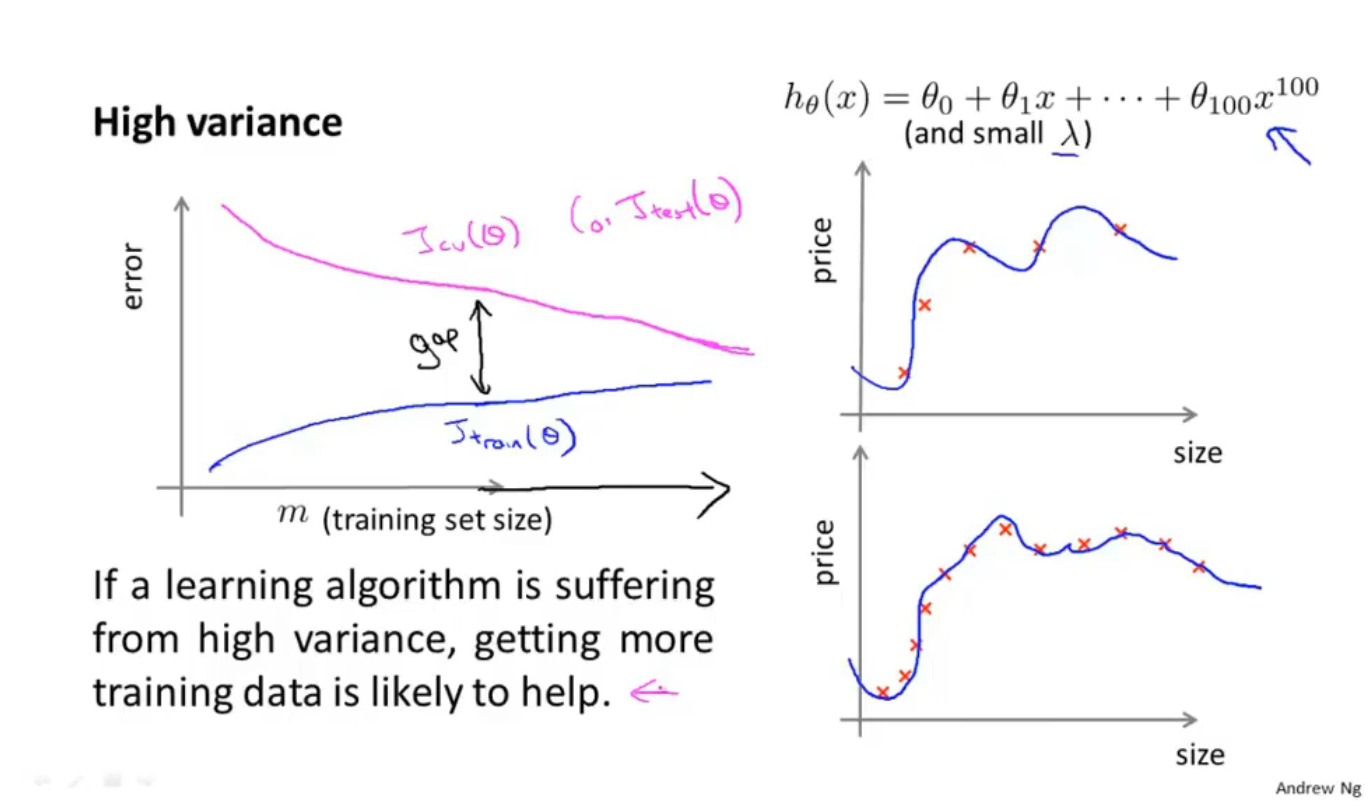
如上图是高方差/过拟合的情形
此时交叉验证集的曲线和训练集的曲线中间相差较大,所以增加数据集数量对于减小误差是有帮助的
10-7 决定接下来做什么
解决高偏差或高方差的一些方法如下图:
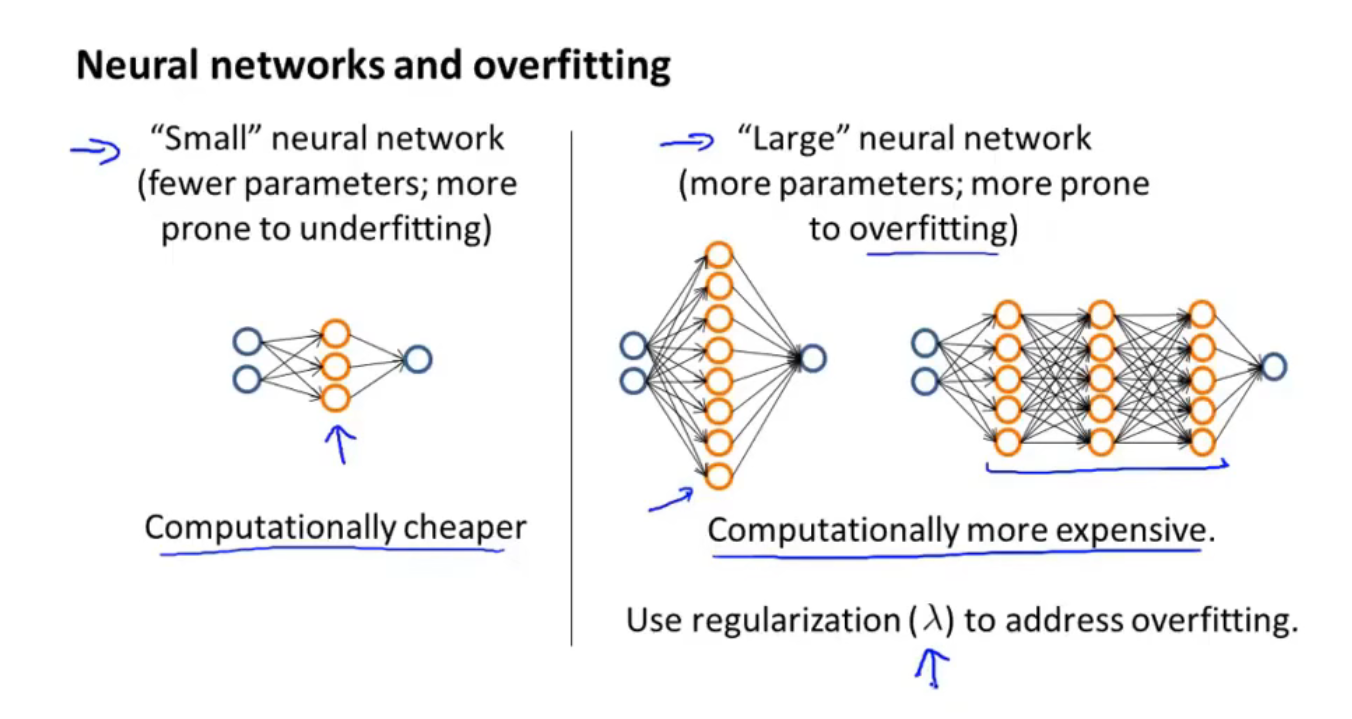
如上图
- 在一个小型的神经网络中,容易出现欠拟合现象,但它的好处是计算量较小
- 在一个大型的神经网络中,容易出现过拟合现象,可以通过正则化来避免,它的好处是效果较好,但是计算量较大


