吴恩达机器学习课程笔记 | 第4章

吴恩达机器学习课程笔记 | 第4章
Justin本系列文章如果没有特殊说明,正文内容均解释的是文字上方的图片
机器学习 | Coursera
吴恩达机器学习系列课程_bilibili
@TOC
4 多变量线性回归
4-1 多特征
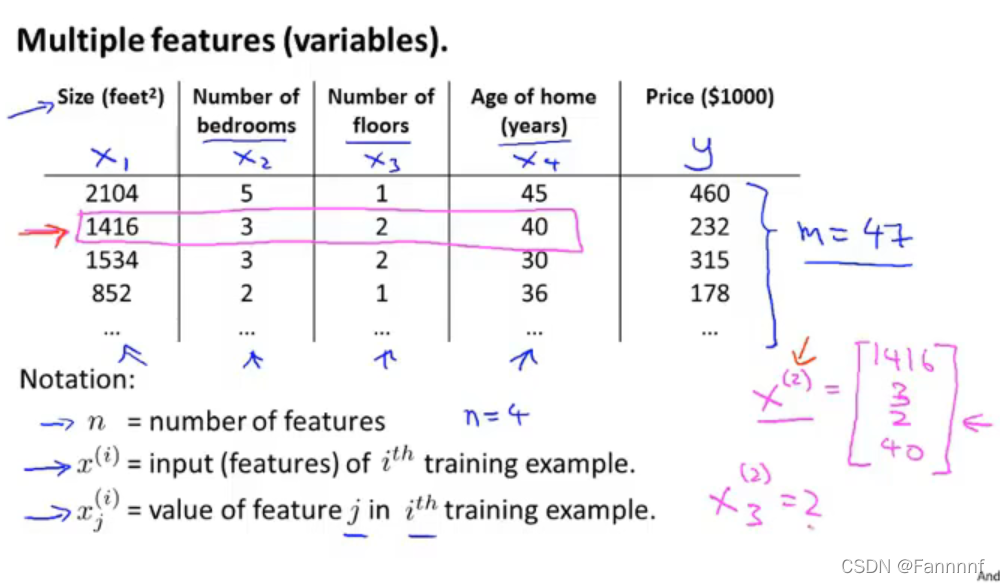
- 用n来表示数据集中特征的数量,这里有4个特征
- y表示输出量
- 用$x^{(i)}$来表示第i行的数据(输入量)
- 用$x^{(i)}_j$来表示第i行的第j个特征

上图是新的假定函数
- $x_1,x_2,x_3……$是多个特征
- 可以假定一个$x^{(i)}_0=1$,这样x和θ就可以写成两个列向量,假定函数就可以写作$θ^Tx$,即求两个矩阵的内积
4-2 多元梯度下降法

- 如上图,从$θ_1$到$θ_n$同步更新,同时特征$x$需要对应
4-3 多元梯度下降法I——特征缩放
缩放
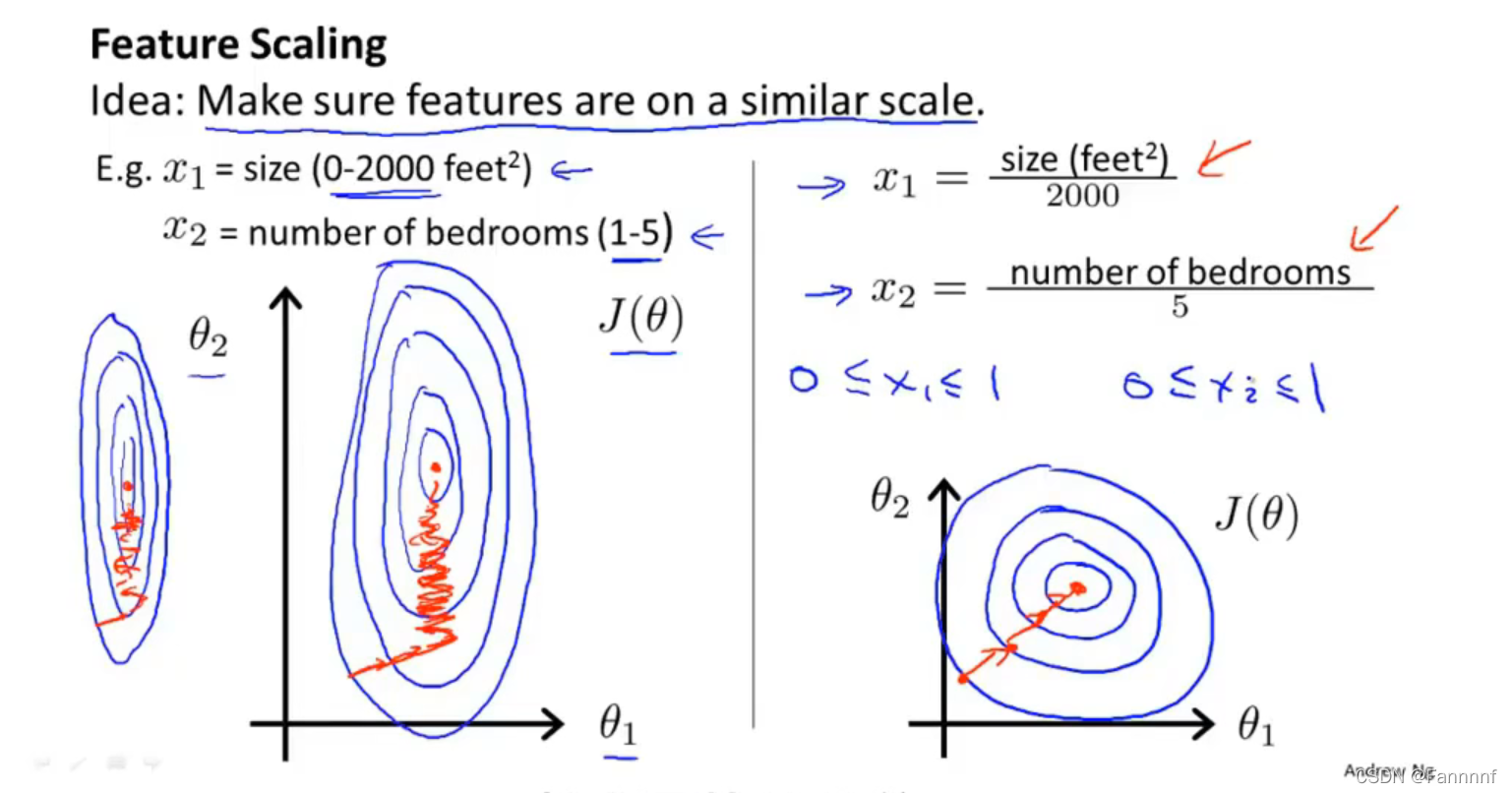
- 这里假设只有两个特征值,特征$x_1$的取值范围是0-2000,特征$x_2$的取值范围是1-5,之后作出的代价函数的等高线图会是一个又高又瘦的椭圆,在进行梯度下降算法时,可能会反复震荡导致收敛太慢,如上图左侧
- 将特征$x_1$和$x_2$缩放,使这两个特征值的范围都在0-1,这样产生的代价函数的图像会变成向上图右侧一样的圆形,这样就会更快地收敛
- 一般会让特征值处于$[-1,1]$范围内,如果比较接近$\pm1$也可以直接计算,不需要进行特征缩放
- 如果特征值过小,如$[-0.0001,0.0001]$也需要进行缩放
归一化

- 如特征$x_1$的平均值为1000,范围为$(0,2000]$,则可以将$x_1$化为$x_1=\frac{size-1000}{2000}$(在这里的例子里$x_1$是房屋的面积)
- 公式为$x_1=\frac{x_1-μ_1}{s_1}$,$s_1$为特征$x_1$原来的范围大小($max-min$),$μ_1$为特征$x_1$原来的平均值
4-4 多元梯度下降法演练I——学习率α
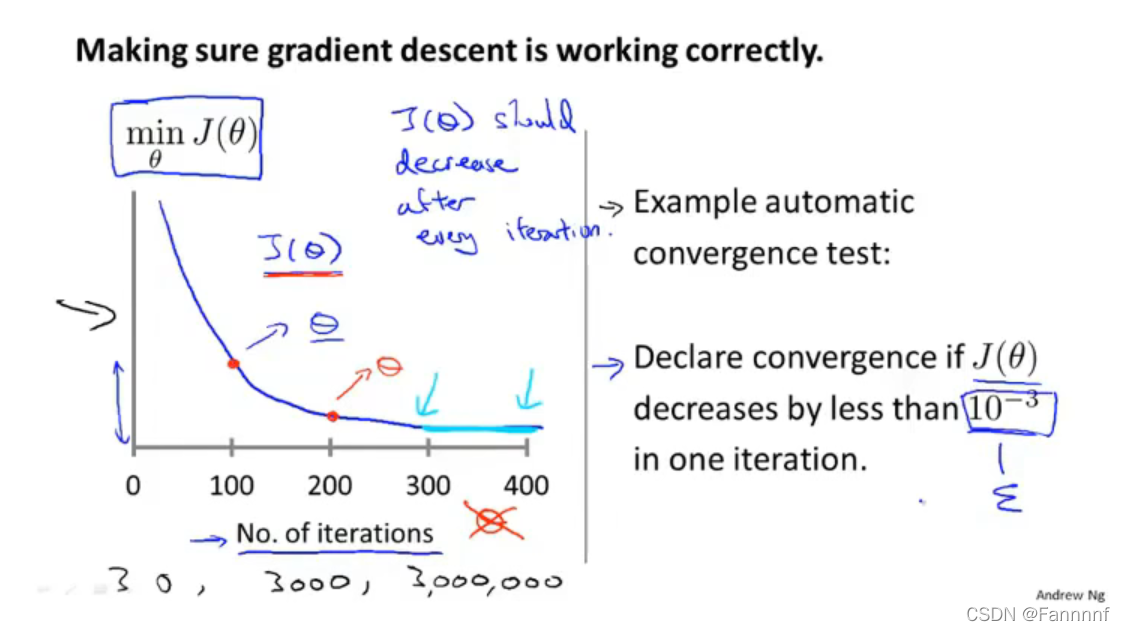
上图左侧纵坐标为计算得出的代价函数的值,横坐标为进行梯度下降算法的次数,次数增加后,代价函数会越来越接近最小值,逐渐收敛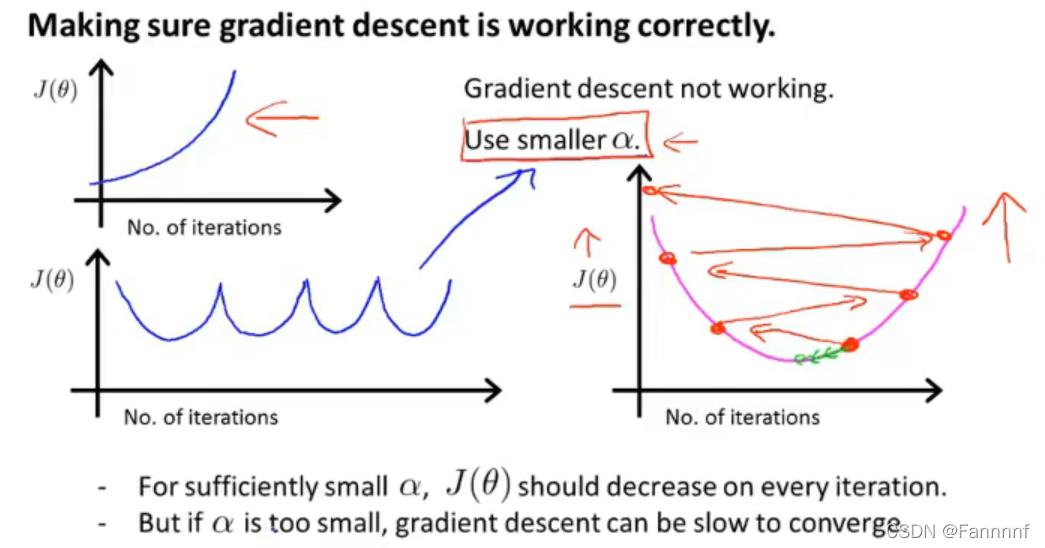
- 如果图像为上图左侧的两种,说明学习率过大,导致像上图右侧一样的变化发散
- 只要学习率足够小,一定会是收敛的(即进行梯度下降算法的次数越多,代价函数一定会越来越接近最小值)
- 学习率过小会导致收敛速度变慢
取学习率时,通常是每隔大约三倍取,如$0.001,0.003,0.01,0.03.0.1,0.3,1$
4-5 特征和多项式回归
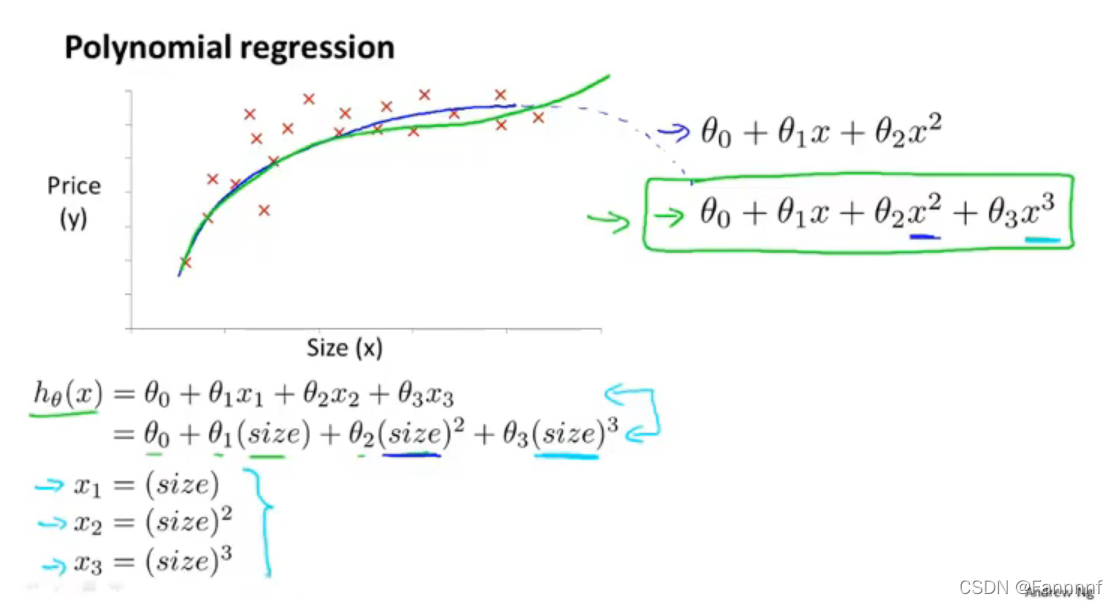
- 用多次的函数来拟合,依然使用之前的一次式,但让$x_1=size$,$x_2=size^2$,$x_3=size^3$
- 或者也可以令假定函数是$h_θ(x)=θ_0+θ_1x_1+θ_2x_2=θ_0+θ_1(size)+θ_2\sqrt{size}$
4-6 正规方程(Normal Equation)(区别于迭代方法的直接解法)
(最小二乘法)
$$θ=(X^TX)^{-1}X^Ty$$
- 使用这个式子不需要进行特征缩放
- $X$为$m×n$的矩阵,$m$为数据数量(training examples),$n$为特征个数

上图是梯度下降算法和正规方程的优缺点
- 在特征数量$n$大于10000左右时,开始考虑不使用正规方程而使用梯度下降算法


