吴恩达机器学习课程笔记第16章

吴恩达机器学习课程笔记第16章
Justin本系列文章如果没有特殊说明,正文内容均解释的是文字上方的图片
机器学习 | Coursera
吴恩达机器学习系列课程_bilibili
@TOC
16 推荐系统
16-1 问题规划
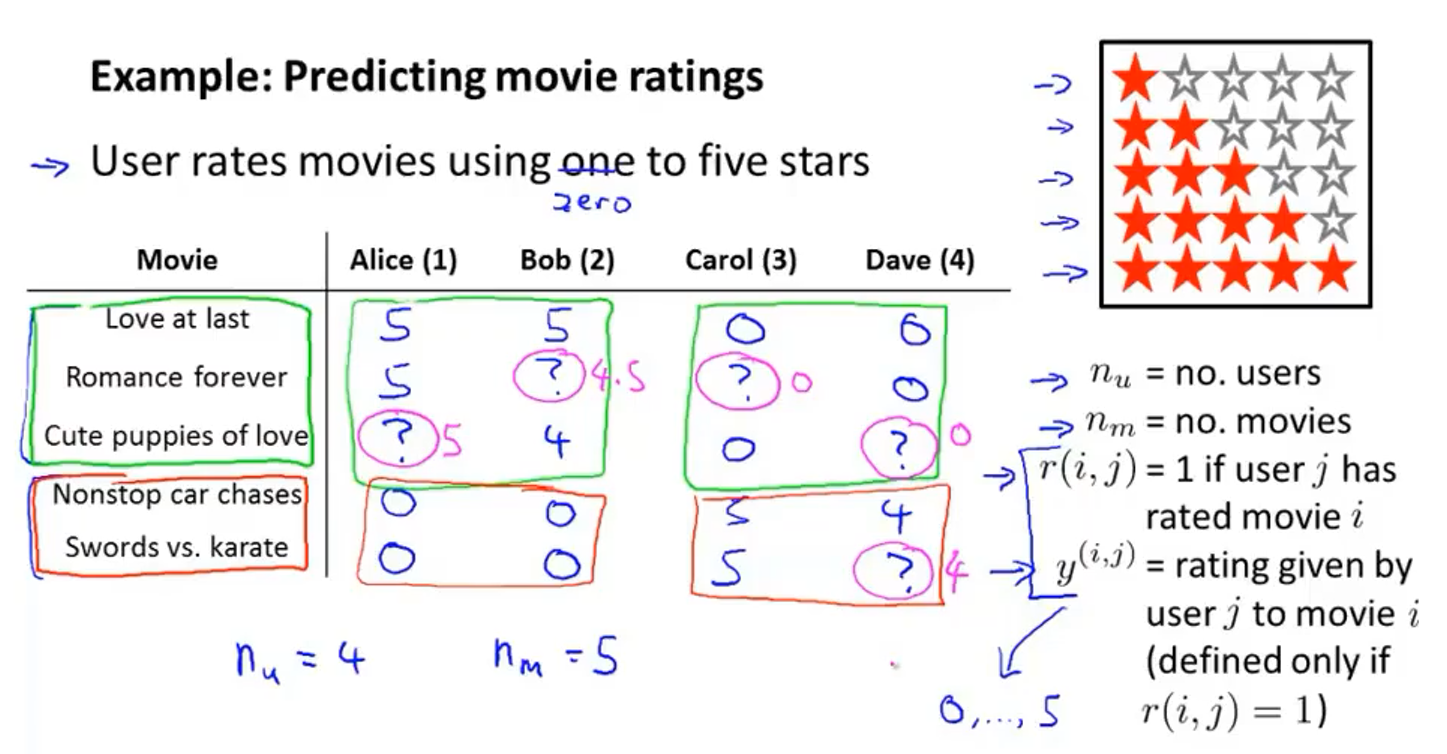
以电影评分预测系统为例,机器学习系统需要预测问号处的值来决定向用户推荐哪部电影
- $n_u$表示用户的数量,这里=4
- $n_m$表示电影的数量,这里=5
- $r(i,j)$:如果用户$j$已经给电影$i$进行评分了的话,$r(i,j)=1$
- $y^{(i, j)}$表示用户$j$给电影$i$的评分(仅在$r(i,j)=1$时才有定义)
16-2 基于内容的推荐算法
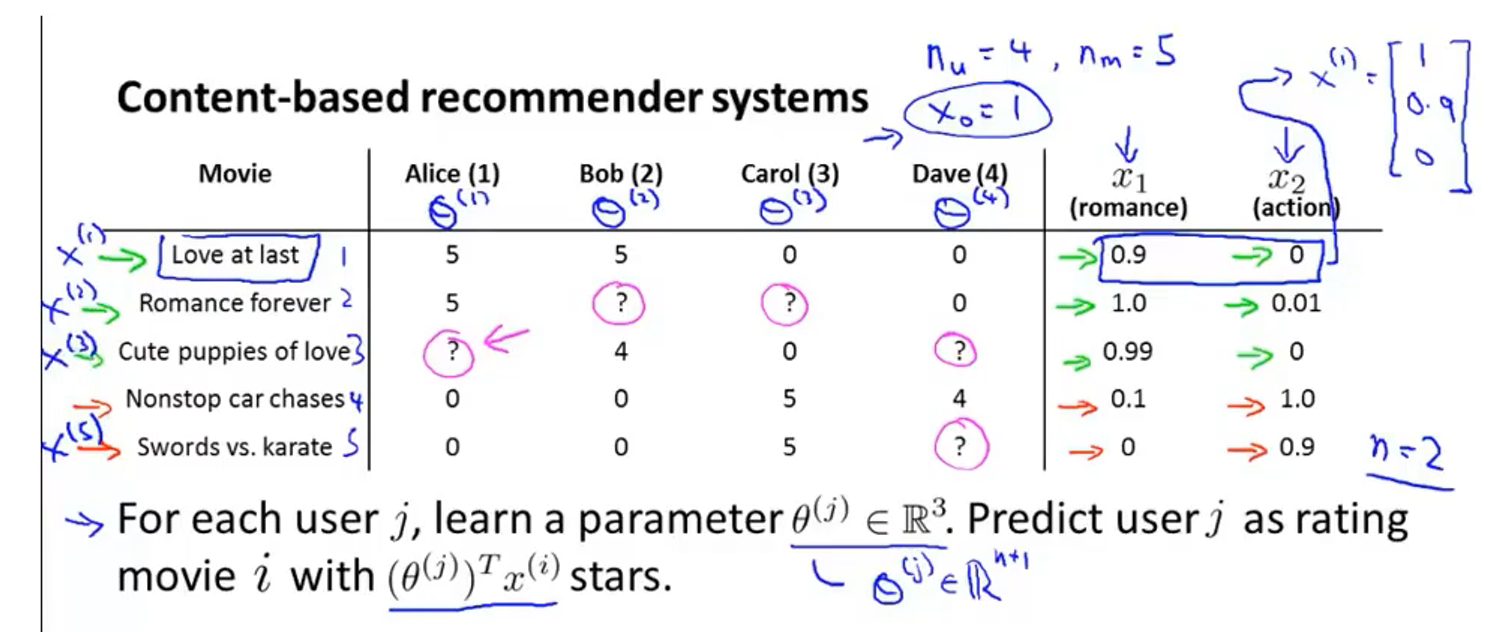
- 用两个特征$x_1$和$x_2$分别表示一部电影的浪漫片程度和动作片程度,组合成矩阵并加上$x_0=1$,比如$x^{(1)}=\left[\begin{array}{l}
1 \
0.9 \
0
\end{array}\right]$,$x^{(i)}$表示的是第$i$部电影的特征向量 - 对每一个用户$j$都学习出一个参数$\theta^{(j)} \in \mathbb{R}^{3}$,预测出用户$j$对电影$i$的评价星级为$\left(\theta^{(j)}\right)^{T} x^{(i)}$
得到推荐算法的代价函数为:
$$\frac{1}{2 m^{(j)}} \sum_{i: r(i, j)=1}\left(\left(\theta^{(j)}\right)^{\top}\left(x^{(i)}\right)-y^{(i, j)}\right)^{2}+\frac{\lambda}{2 m^{(j)}} \cdot \sum_{k=1}^{n}\left(\theta_{k}^{(j)}\right)^{2}$$
其中$m^{(j)}$表示用户$j$评价了的电影数量
$\sum_{i: r(i, j)=1}$表示累加所有满足$r(i, j)=1$的项,变化$i$
为了简化计算,一般去掉$m^{(j)}$项,代价函数变为:
$$\frac{1}{2 } \sum_{i: r(i, j)=1}\left(\left(\theta^{(j)}\right)^{\top}\left(x^{(i)}\right)-y^{(i, j)}\right)^{2}+\frac{\lambda}{2 } \cdot \sum_{k=1}^{n}\left(\theta_{k}^{(j)}\right)^{2}$$
要优化所有用户的参数,代价函数改为:
$$J\left(\theta^{(1)}, \ldots, \theta^{\left(n_{u}\right)}\right)=\frac{1}{2} \sum_{j=1}^{n_{u}} \sum_{i: r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)}\right)^{2}+\frac{\lambda}{2} \sum_{j=1}^{n_{u}} \sum_{k=1}^{n}\left(\theta_{k}^{(j)}\right)^{2}$$
梯度下降更新项如上↑
16-3 协同过滤
由于之前的推荐算法的数据集中是给定了每部电影的特征,而一般一部电影的特征是难以判断的,所以需要协同过滤
来自动学习特征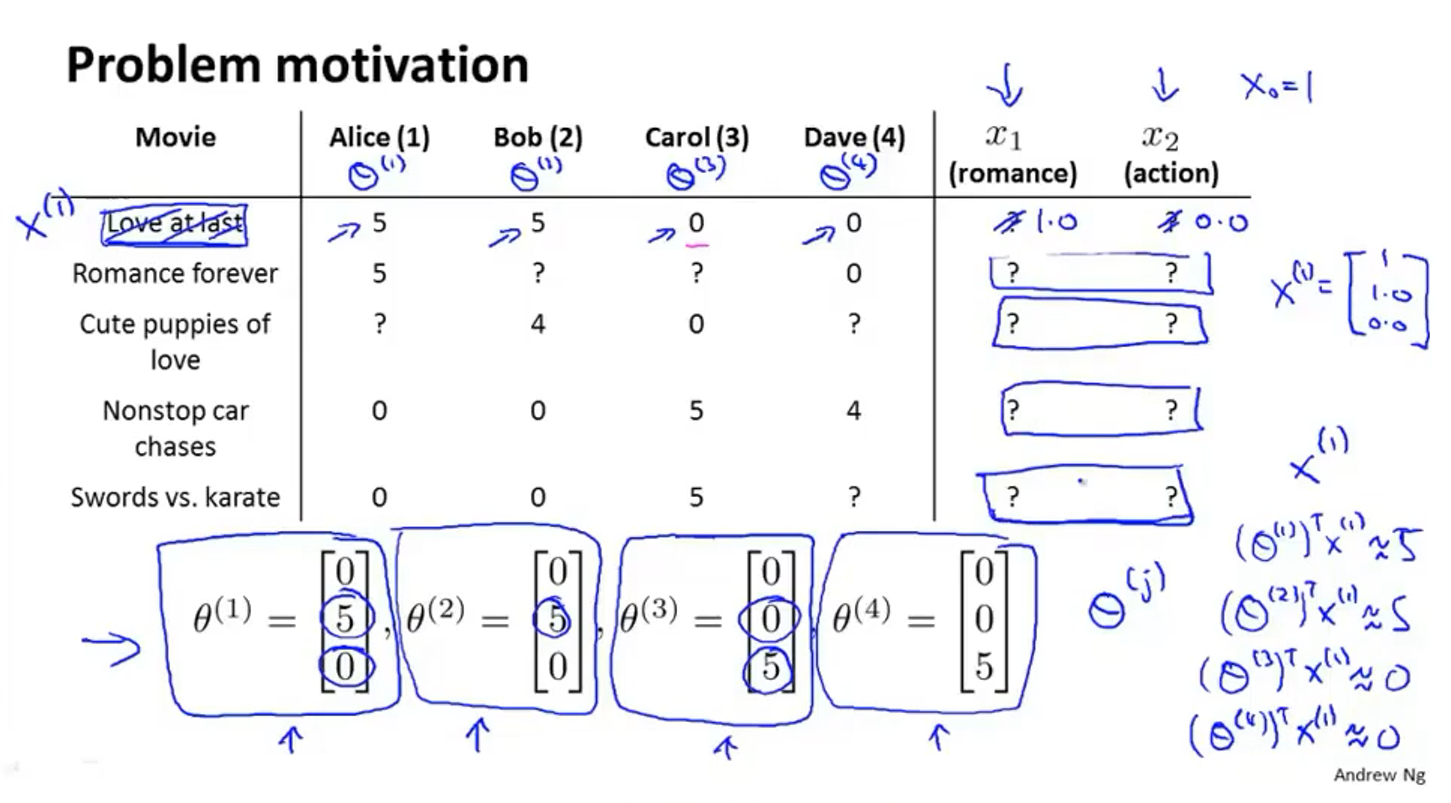
调查每位用户对电影类型的喜好得到参数矩阵$\theta$,比如$\theta^{(1)}=\left[\begin{array}{l}
0 \
5 \
0
\end{array}\right]$表示的是用户1对$x_1$表示的浪漫片有5的喜爱,对$x_2$表示的动作片有0的喜爱,矩阵第一项的存在是因为有$x_0=1$这一项
根据用户给出的对一类电影的喜爱程度、用户给出的对电影的评分,就可以计算每一部电影的特征值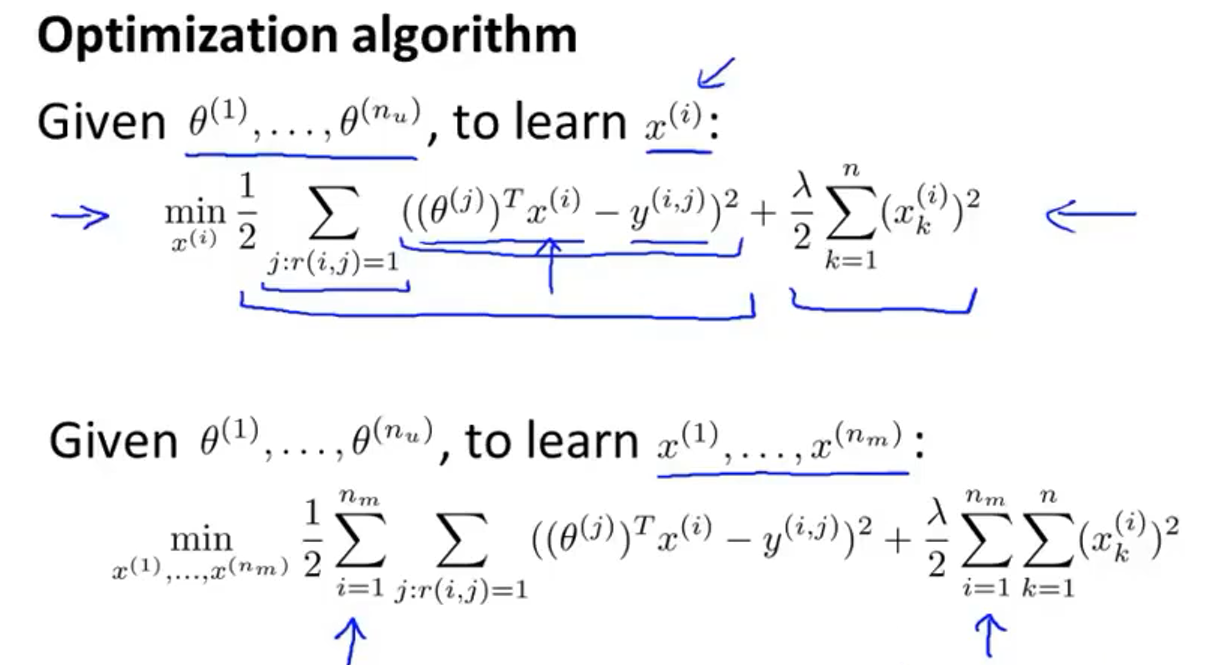
通过上图的代价函数计算出每一部电影的合适的特征
先猜测一组参数$\theta$,然后计算出电影的特征$x$,再根据此特征计算新的参数$\theta$,再计算出电影的特征$x$,这样不断循环,最后就能收敛
16-4 协同过滤算法
去掉$x_0=1$和$\theta_0=1$,让$x \in \mathbb{R}^{n}$,$\theta \in \mathbb{R}^{n}$
把求$\theta$和求$x$的两个代价函数合起来,得到一个新的不需要像上一节一样循环往复的代价函数:
$$
J\left(x^{(1)}, \ldots, x^{\left(n_{m}\right)}, \theta^{(1)}, \ldots, \theta^{\left(n_{u}\right)}\right)=\frac{1}{2} \sum_{(i, j): r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)}\right)^{2}+\frac{\lambda}{2} \sum_{i=1}^{n_{m}} \sum_{k=1}^{n}\left(x_{k}^{(i)}\right)^{2}+\frac{\lambda}{2} \sum_{j=1}^{n_{u}} \sum_{k=1}^{n}\left(\theta_{k}^{(j)}\right)^{2}
$$
上图是协同过滤算法的全过程:
- 初始化$x$和$\theta$为一个很小的值
- 用梯度下降或其他优化算法最小化代价函数
- 得出最后的$x$和$\theta$即可计算某个用户未评价的电影的可能的评价星级
16-5 向量化:低秩矩阵的分解
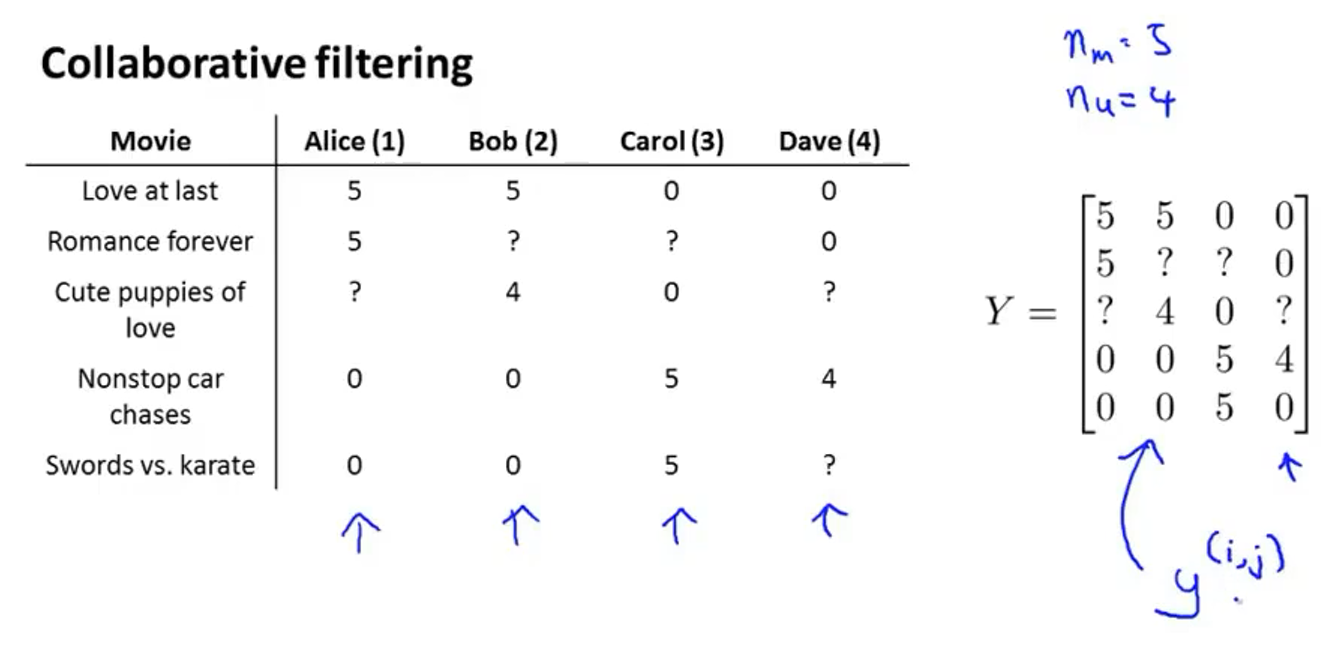
首先把上图的数据表写成矩阵$Y$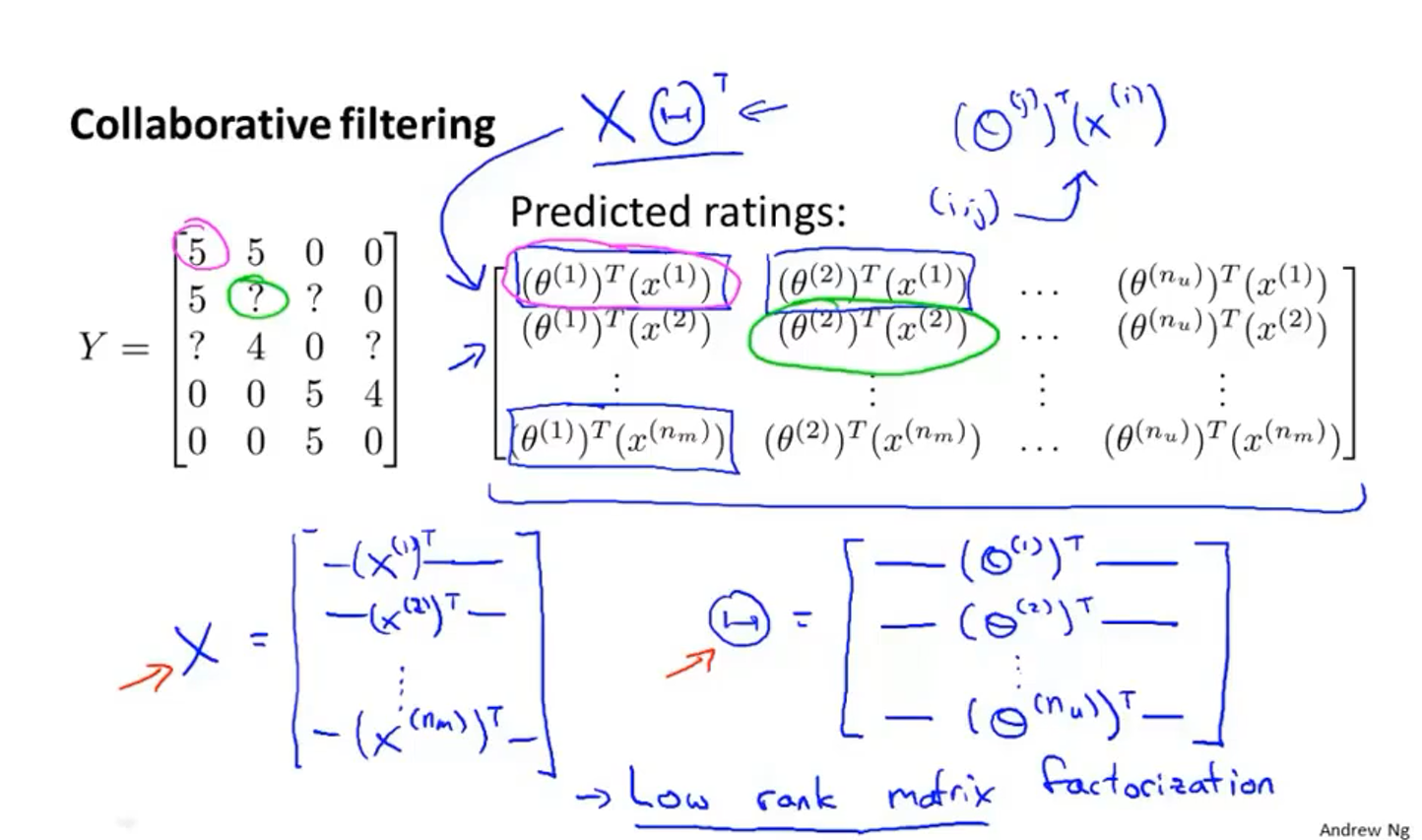
矩阵$Y$中的每一个元素都是由公式$\left(\theta^{(j)}\right)^{\top}\left(x^{(i)}\right)$计算得出的
矩阵$X$和矩阵$\Theta$由上图所示的元素组成,所以矩阵$Y$可以表示为$Y=X \Theta^{T}$
如何找到跟一部电影相似的另一部电影?
- $\left|x^{(i)}-x^{(j)}\right|$越小,表示电影$i$和电影$j$越相似
16-6 实施细节:均值归一化
如果一位用户没有对任何一部电影评分,那么会得出预测他对所有电影的评分都为0的荒谬结果,所以需要均值归一化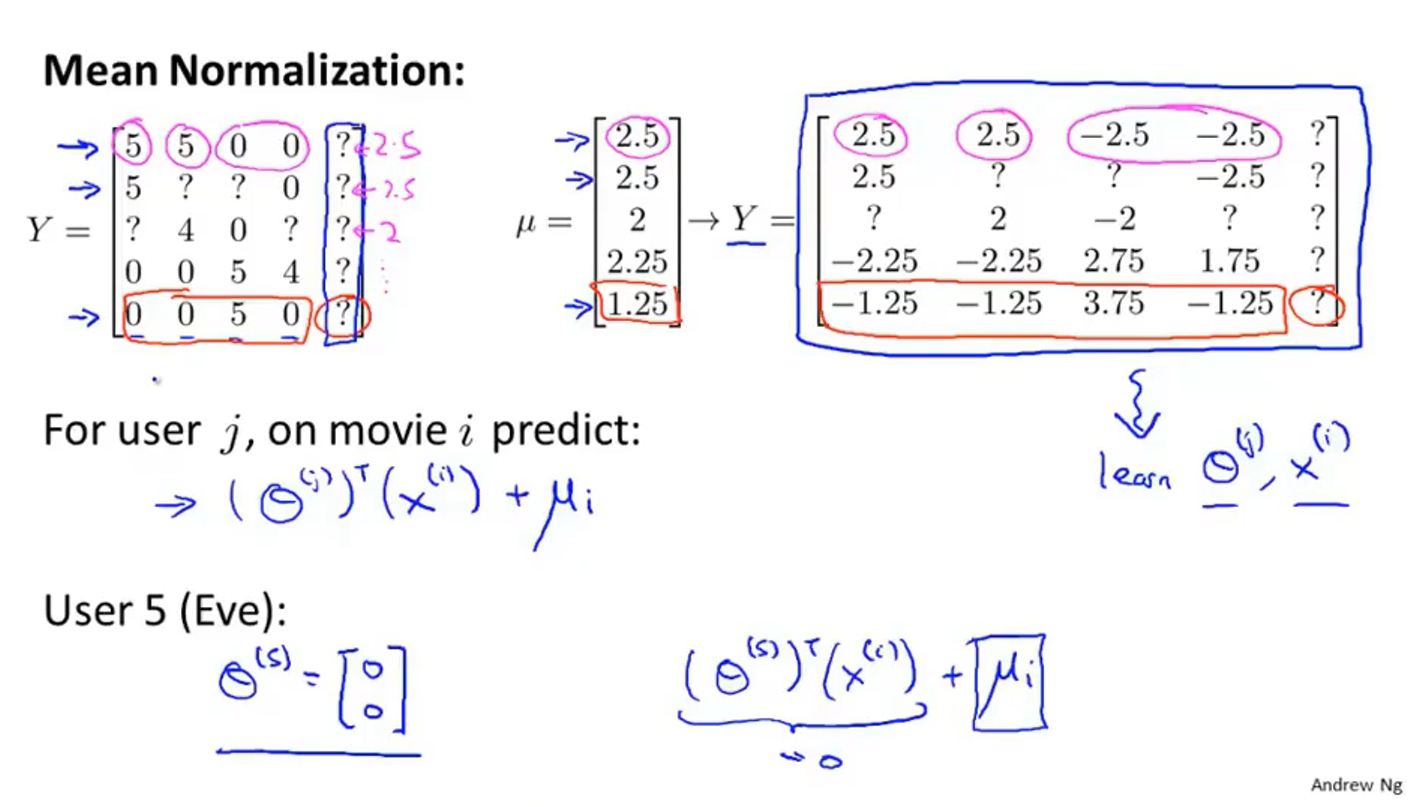
如上图所示,跟上一节相同的矩阵$Y$,求每一部电影的评分均值得到矩阵$\mu$,然后把矩阵$Y$中的每一项都减去矩阵$\mu$中对应的电影的平均值,得到新的矩阵$Y$,按照新的矩阵来学习出$\theta^{(i)}$和$x^{(i)}$,最后在计算某一个未知的评分时需要用公式$\left(\theta^{(j)}\right)^{\top}\left(x^{(i)}\right)+\mu_{i}$,(因为之前平均值被减掉了,所以现在要加回去),这样预测用户5时得到的结果就不再时0,而是预测的电影的评分平均值


