吴恩达机器学习课程笔记第17章

吴恩达机器学习课程笔记第17章
Justin本系列文章如果没有特殊说明,正文内容均解释的是文字上方的图片
机器学习 | Coursera
吴恩达机器学习系列课程_bilibili
@TOC
17 大规模机器学习
17-1 学习大数据集
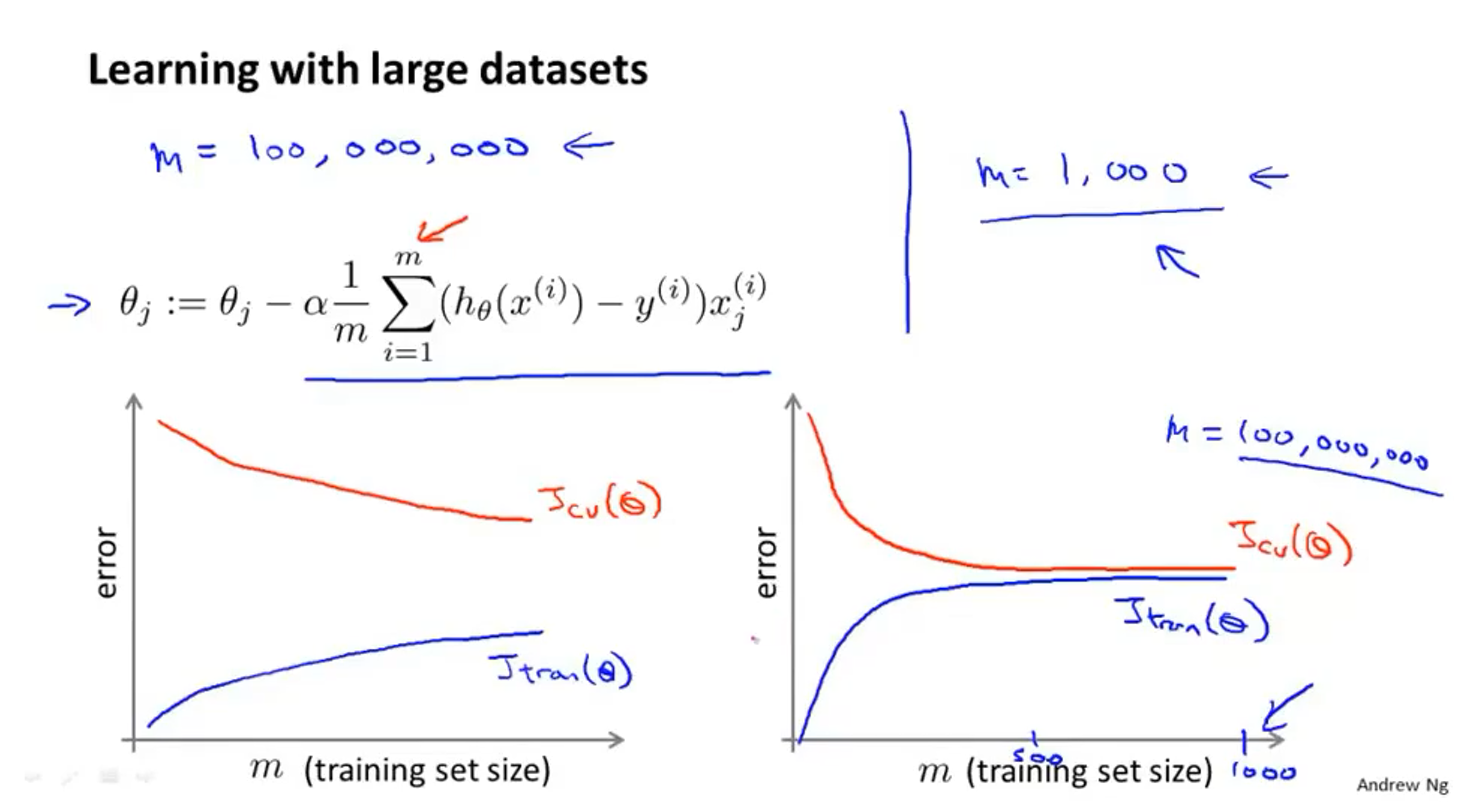
- 如果数据集中有1亿个样本,那么梯度下降算法的计算量会变得很大
- 如果训练效果(误差)的图像是像左边的坐标系一样的话,那么1亿个样本的数据集训练的效果很可能会比1000个样本的数据集好
- 而如果图像像右边的坐标系一样的话,1000个样本的数据集很有可能训练效果跟1亿个样本的数据集差不多
17-2 随机梯度下降
原来的梯度下降算法称为批量梯度下降算法(batch gradient descent),因为要对所有样本遍历
下面描述随机梯度下降算法(stochastic gradient descent)
以线性回归为例,代价函数为:$J_{\operatorname{train}}(\theta)=\frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2}$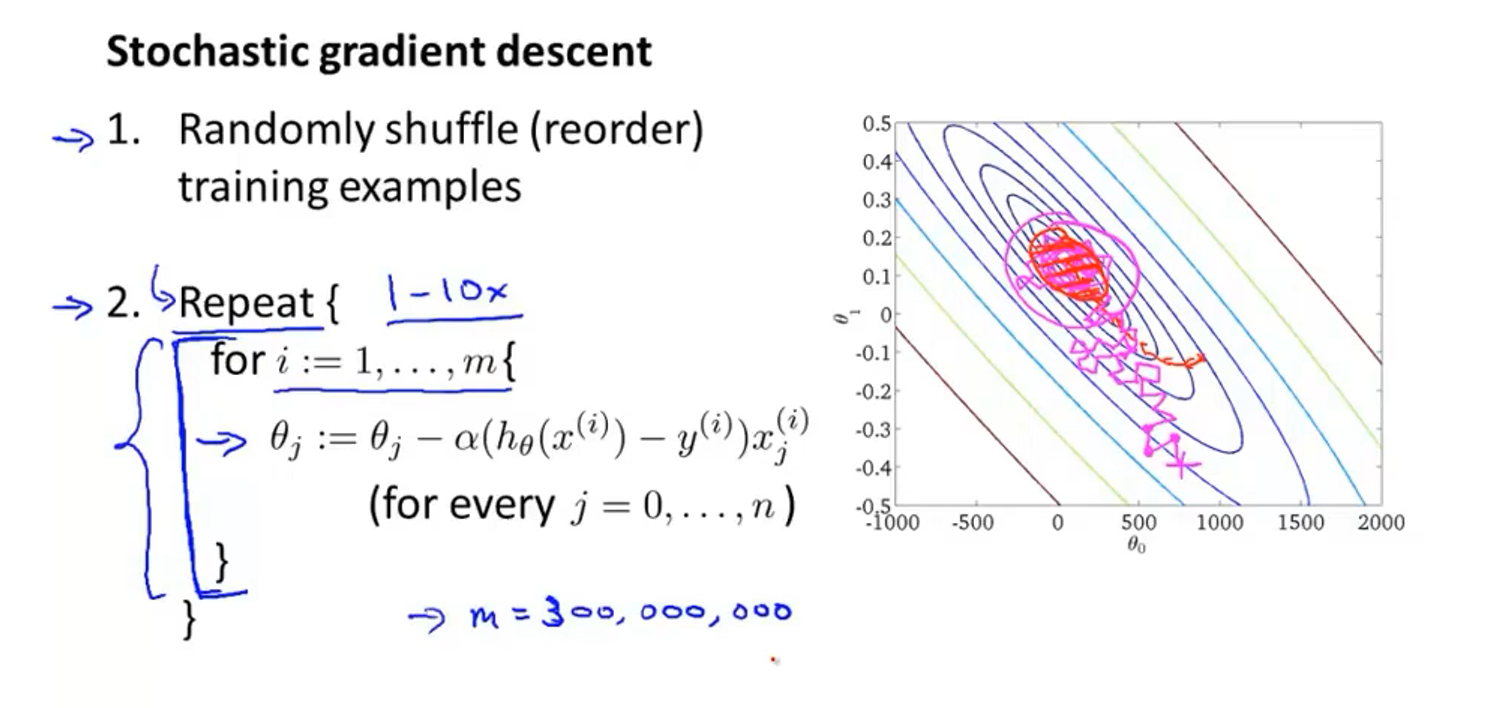
随机梯度下降的过程:
1.随机打乱所有数据(将所有样本重新随机排列)
2.重复上图中的循环(最外层的Reapt循环可能需要1到10次)
- 随机梯度下降算法的每一步怎么走取决于遇到的那个数据集,所以随机梯度下降算法向中心靠拢的过程是迂回的,不一定每次都是向中心靠拢的
- 而原来的梯度下降算法由于每一次都遍历了整个数据集,所以他每一次都是向中心靠拢的
每一次更新参数值都是根据一个样本来更新的,如果第一个样本和第二个样本很相近,那么第一个样本更新完的参数值到第二个样本的时候,第二个样本的cost函数(即更新参数那个公式里面减掉的那项)几乎接近于0了,那么就不会怎么更新参数值了
这个算法应该会先过拟合然后再逐渐的到好的拟合
17-3 mini-batch 梯度下降

- batch梯度下降算法中每一次下降用到了全部的m个样本
- 随机梯度下降算法中每一次下降用到了1个样本
- mini-batch梯度下降算法中每一次下降用到b个样本
- b称为mini-batch size,一般取值为10,一般取值范围为2到100

假设取值为b=10
算法如上图所示
17-4 随机梯度下降收敛

在随机梯度下降算法中,如何判断是否已经收敛?
- 在每次要更新$\theta$之前,计算这个样本的cost函数
- 每经历了1000次循环迭代(遍历了1000个样本),就把这1000(也可以是前5000之类的)个样本的cost函数的平均值输出出来
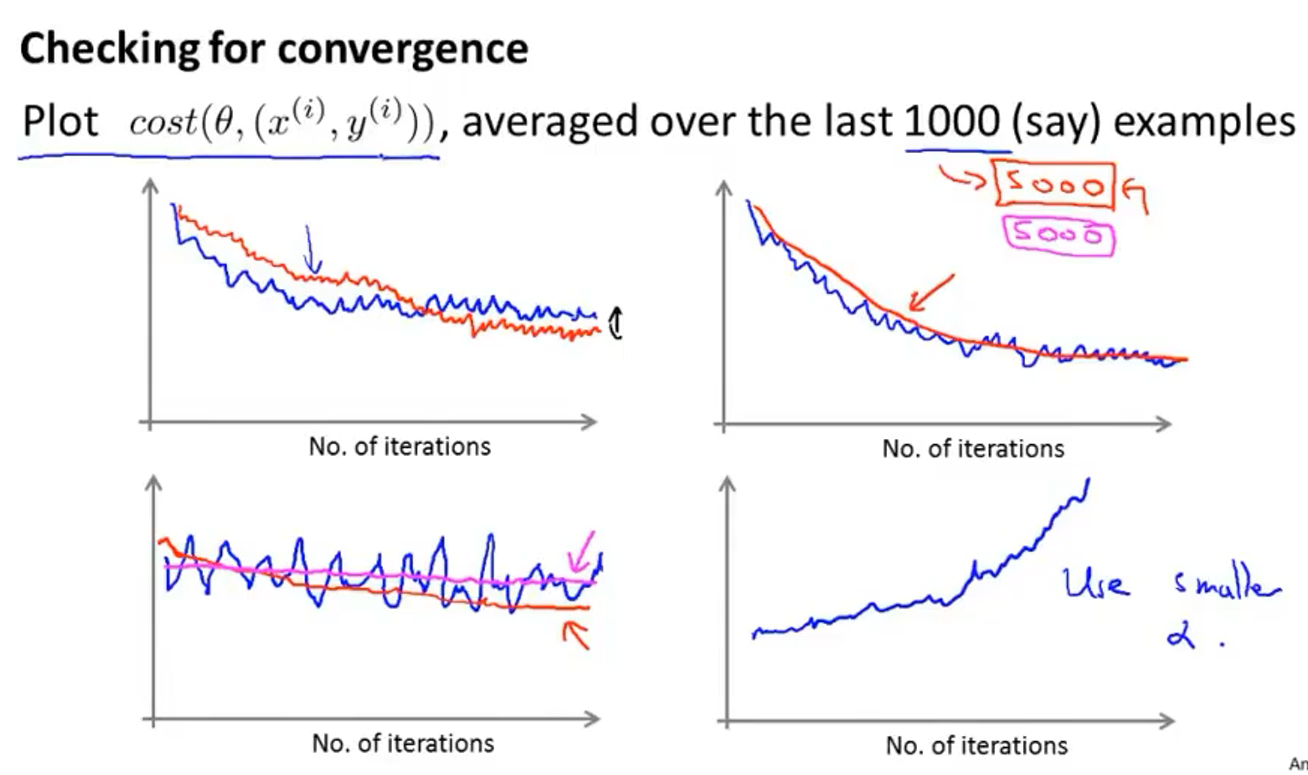
上图是画出的图像
- 如果是像左上角的图像,那么说明算法正在收敛,如果用一个大的学习率$\alpha$,那么可能得到左上角蓝色的曲线,如果用小的,就可能是红色的曲线(收敛相对比较慢,但震荡的比较小)
- 右上角蓝色曲线表示取1000次输出一次cost函数的均值的曲线,红色曲线表示取5000次(曲线会比较平滑,但反应会比1000次的慢)
- 左下角蓝色曲线表示取1000次(看起来是震荡的没有收敛,但是如果换成取5000次可能就能看到红色的曲线:正在收敛,只是比较慢),但也有可能看到粉色曲线,表示函数没有在收敛
- 右下角的曲线表示函数是发散的,可能需要缩小学习率$\alpha$

一般学习算法中的学习率$\alpha$是一个常数,所以一般代价函数的值会在最小值附近震荡,但是如果想要更加靠近最小值的话,可以定义学习率$\alpha$为$\alpha=\frac{\text { 常数1 }}{\text { 循环次数 }+\text { 常数2 }}$,让$\alpha$随着循环次数的增加而逐渐变小
由于这个方法需要再额外确定两个参数,所以这个方法用的很少,因为原来的结果已经足够满意了
17-5 在线学习机制
可以解决有连续的数据流,想要用算法从中学习的问题
以寄快递网站为例:用户在网站上用确定的目的地和始发地来查询寄件费用,有时用户会选择服务(得到一个正样本$y=1$),有时不会选择(得到一个负样本$y=0$),需要我们预测选择我们的服务的概率来给出一个合理的价格
每次多一个数据就更新一次参数值,跟之前的随机梯度算法很像
这样的优点是能不断适应和更新用户的选择变化来调整输出值,但只能适用于有很多用户数据流入的情况,如果用户数据很少,不能用这样的算法
上图解释了点击率预测问题(CTR)的实现
17-6 map-reduce和数据并行

假设用批量梯度下降算法
假设训练集中共有400个样本即m=400,那么梯度下降算法中就需要对400个数据进行求和
将训练集分为4份,用4台电脑分别求和第1-100、101-200、201-300、301-400的数据,求和完后再汇总到一台主机上对4个数据进行求和,再进行接下来的运算,这样运算效率就是原来的4倍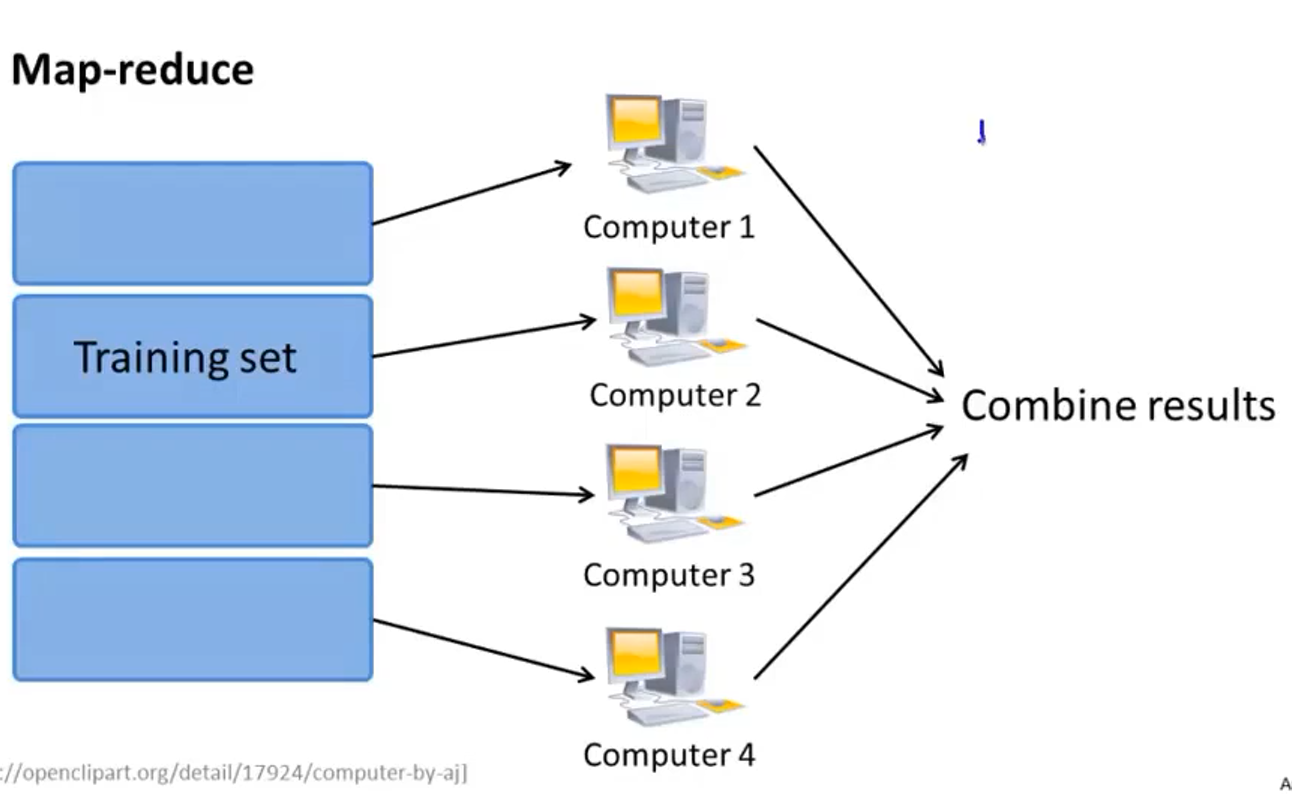
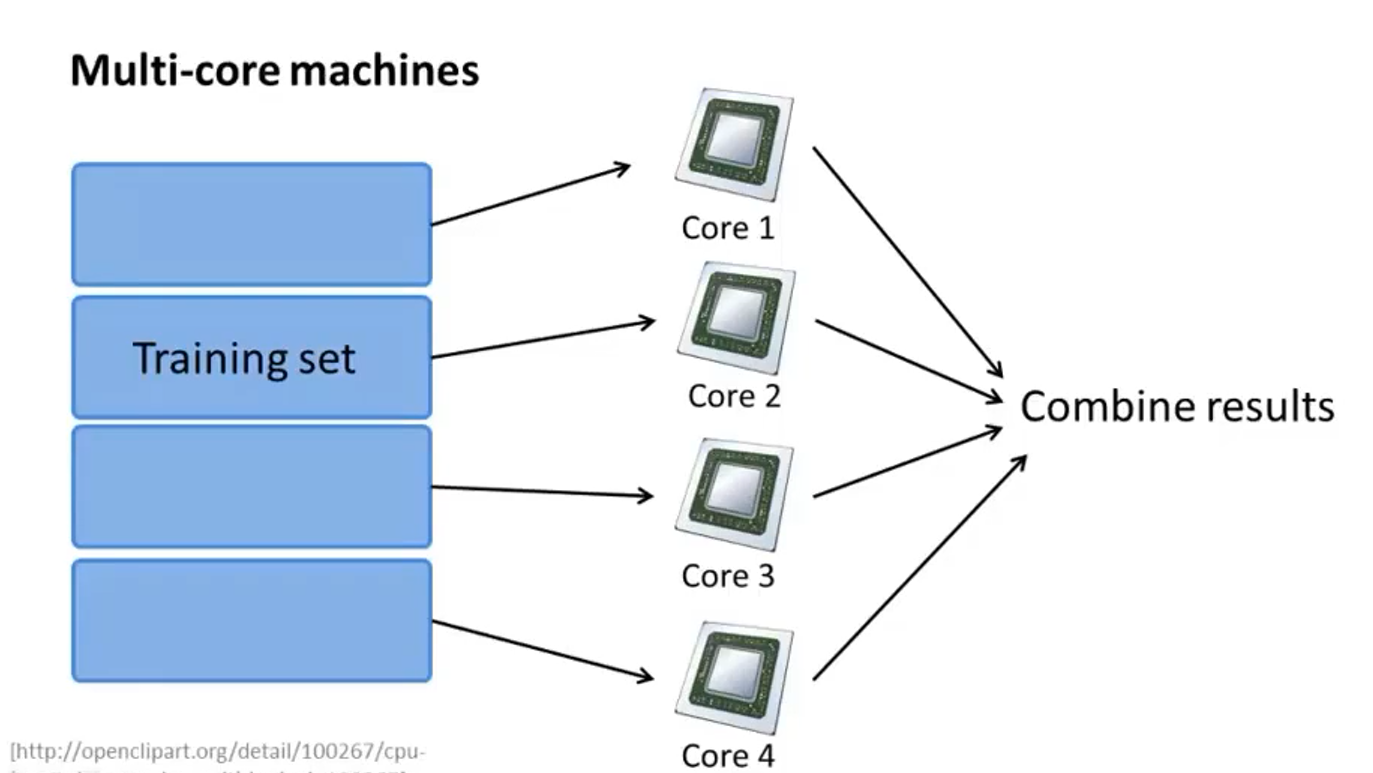
- 只要运算中有求和操作就可以用map-reduce来做
- map-reduce也可以应用于一台电脑上的多核cpu
- 一般向量化后直接调用线性代数库来运算,有些线性代数库在计算中会自动用map-reduce分配多核分工完成计算


